I’m running LCModel using MRS data from a General Electric scanner (3T, Signa HDxt), therefore using “GE Signa LX” as data type. Most P files are read correctly, but those acquired with the same scanner from a specific date onwards can’t be read by LCModel, due to “incorrect size of file”:
I wonder if there might be an issue with the header of files resulting in this error. In case anyone encountered a similar problem or is willing to take a look, I attach an example P file resulting in this error.
GE headers change occasionally when the GE software receives an update. The LCModel source code hasn’t been updated in years, so unless you find someone who understands Fortran well enough to modify the source and compile a new executable, you won’t be able to feed the P files directly into LCModel.
Your best option is probably to load (and process) these datasets with newer software that receives regular updates (Osprey, FSL-MRS, spant, etc.) and export them into the LCModel .raw format, which all of the above should be able to do.
Do you know what scanner software release are you running? And just to be sure, do you have the most recent version of LCModel and utilities (from here)?
Assuming you’re using a fairly standard sequence, that conversion tool (gelx/bin2raw) should work at least up to and including DV29 (and possibly 30… as far as I know the header is unchanged, but the version number may be enough to confuse the import tool into thinking it can’t read it).
…also if I’m not mistaken, only the source code for the main LCModel program has been released, without any of the ancillary tools (data conversion etc). So realistically, I wouldn’t hold much hope for the import being updated. In any case, any of the software suggested by @admin will have more up-to-date methods for pre-processing, so it’s probably best to transition towards one of those approaches anyway.
Thank you all for your response. I will try processing these files with other software options.
@alex, unfortunately I am not aware of the scanner software release that was used during acquisition of these data, but the P files resulting in errors were acquired from 2012 on, so they are not “that recent”. I do have the latest LCModel version.
Sorry, I didn’t notice your uploaded data before. It’s an older software release (rev 16, 2018 datestamp), but oddly enough still won’t load with the most recent LCModel import. You may have been running some less-common software release which was never supported, for whatever reason.
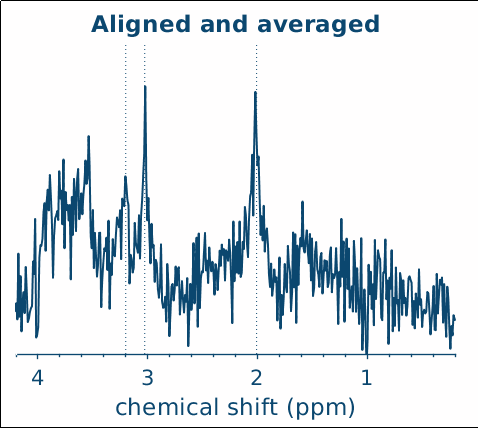
Both FSL-MRS (spec2nii) and Osprey load this without any trouble – although, at first glance this does not look like great data: very small voxel and low number of repetitions, so it’s extremely noisy.
I’m opening this topic again because I followed your advice to open in Osprey the files that couldn’t be read by LCModel (due to the header issue). After processing these .7 files in Osprey, I’m using the saved .raw files in “LCModelFiles/metabs” as the main sequence, and the ones in “LCModelFiles/ref” as the water unsupressed sequence.
However, I compared the LCModel results from P files without this header issue, with LCModel results from the .raw files derived from the same P file with Osprey, and the results are not coincident (regardless of whether I use eddy-current correction or not).
I was wondering if I’m doing anything wrong with the configuration I’m using or with the .raw files I’m selecting?
Thank you very much for your help!
Best wishes,
Diana.
Are you using the same control file that Osprey generates to pass on to LCModel? (You can check them in the LCModelControlFiles folder in the output folder).
LCModel results (like all MRS modeling) depend very strongly on settings and decisions made about the analysis procedure. Osprey makes a lot of (hopefully sensible) assumptions that sometimes override LCModel defaults, so I would absolutely expect differences to ‘vanilla’/default LCModel settings.
Most importantly, Osprey undoes the very crude (and in almost all cases not appropriate) water scaling procedure that LCModel attempts, which is based on a pure white matter voxel and does not attempt to account in any way for tissue composition (which Osprey performs afterwards), so the water-scaled estimates between Osprey-called LCModel and ‘vanilla’ LCModel are absolutely guaranteed to be different. tCr ratios might be comparable.
Thanks a lot for you reply. Exactly, I’m not calling LCModel from Osprey but using the .raw files as direct inputs to LCModel. Now I understand why both are different, and from your comments I assume that processing with Osprey first (and using both the resulting .raw and the control files) would be the best way to go with all P files, right?
(Or rather, just getting concentrations directly with Osprey)
Yeah, I think I wouldn’t mix native P files with processed raw files, even if you use the same control file. Maybe just drag them all through Osprey first, even the ones that would work straight away?