Long term LCModel user, testing Osprey on our data. Seeing some difference in fitting between the two and would appreciate some comments.
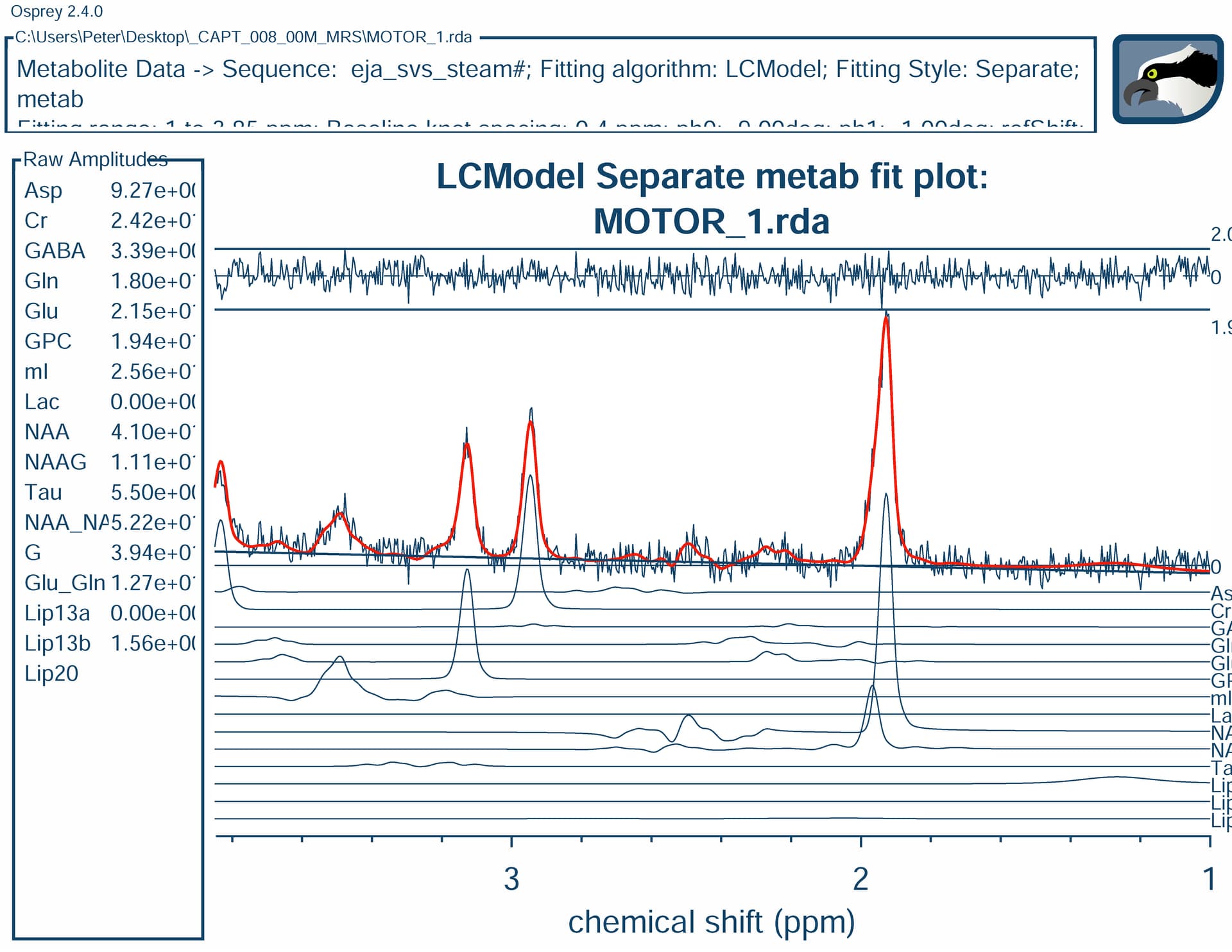
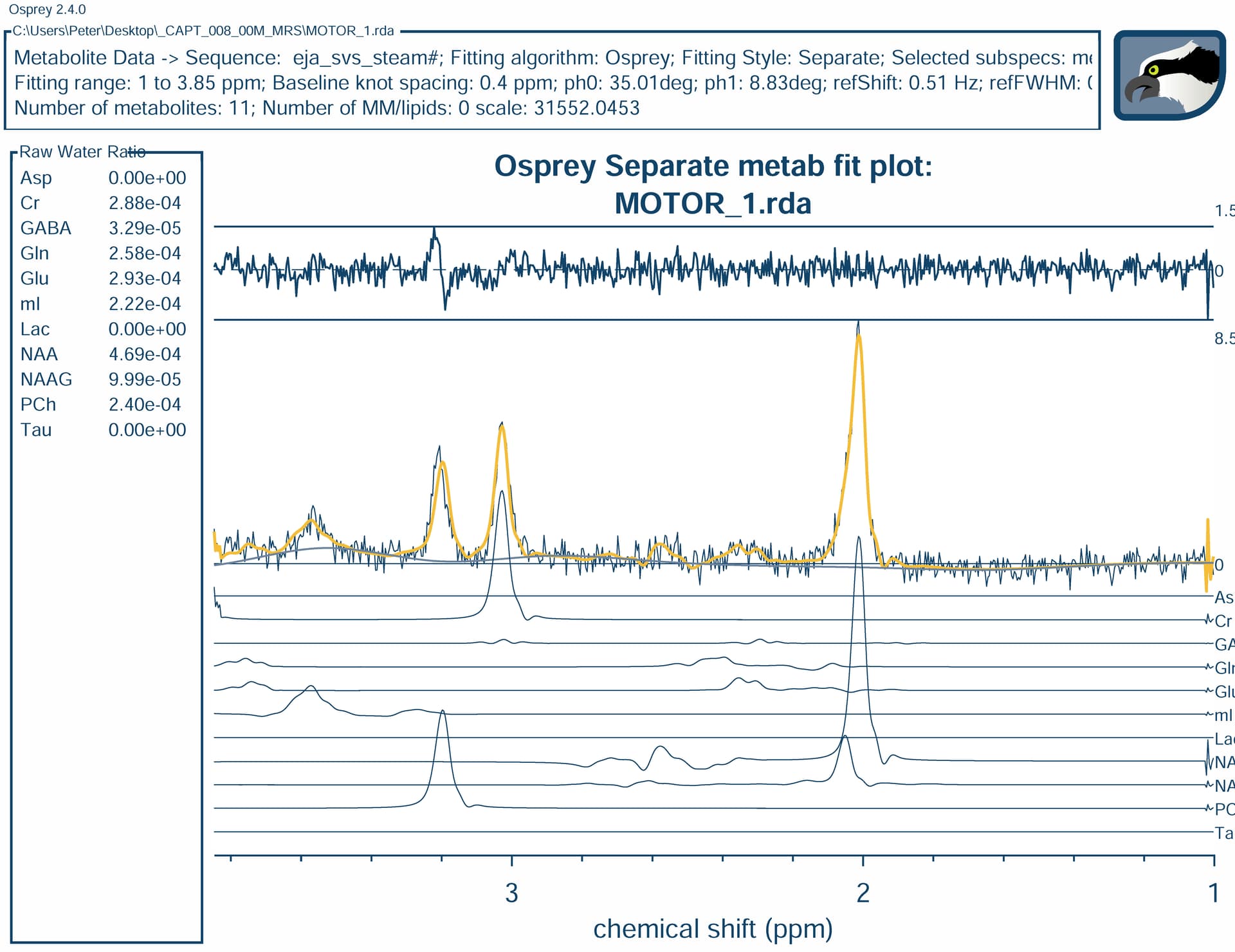
Using STEAM (TE=160ms) dataset, with basis set developed for LCModel, converted to Osprey. Output from my version of LCModel (6.3-1L) (not shown) is similar to Osprey/LCmodel fit (which I think uses 6.3-1N version), but Osprey/Osprey fit is a bit different, especially for Choline, leaving some residual. Any suggestions to improve Osprey/Osprey fit?
Thanks for giving Osprey a shot - I’m glad you discovered the built-in LCModel binary which you could opt for if you would like continuity.
I am noticing that your LCModel fit seems to include GPC, whereas the Osprey one has PCh - neither of them uses both. I’m also noticing some truncation artefacts on the edge of the Osprey basis spectrum which I have a hard time understanding without knowing how you converted your LCModel basis set. Then again, they shouldn’t affect the main estimation too much. Osprey does usually allow small frequency shifts (just like LCModel), and I don’t quite know why it doesn’t pick them up here. Instead it seems to try and compensate with a little lineshape convolution (which is, unlike LCModel, not regularized).
I don’t expect the same fit, let alone the same values - but appreciate the explanation of difference in fitting - interesting that the small frequency shift is not (fully) applied in Osprey fit.
I’ve translated our “Cho” as either “PCh” or “GPC” when converting LCModel basis set to Osprey - the results are the same.
I would eventually like to understand FID-A enough to create a new basis set, but that’s a whole another can of worms. We’ve been using our in-house simulator, but it’s not an easy one to use (either).
I should be able to help you out with the basis set if you have the exact pulse timings and durations for the Eddy Auerbach STEAM sequence… feel free to drop me a line through e-mail!