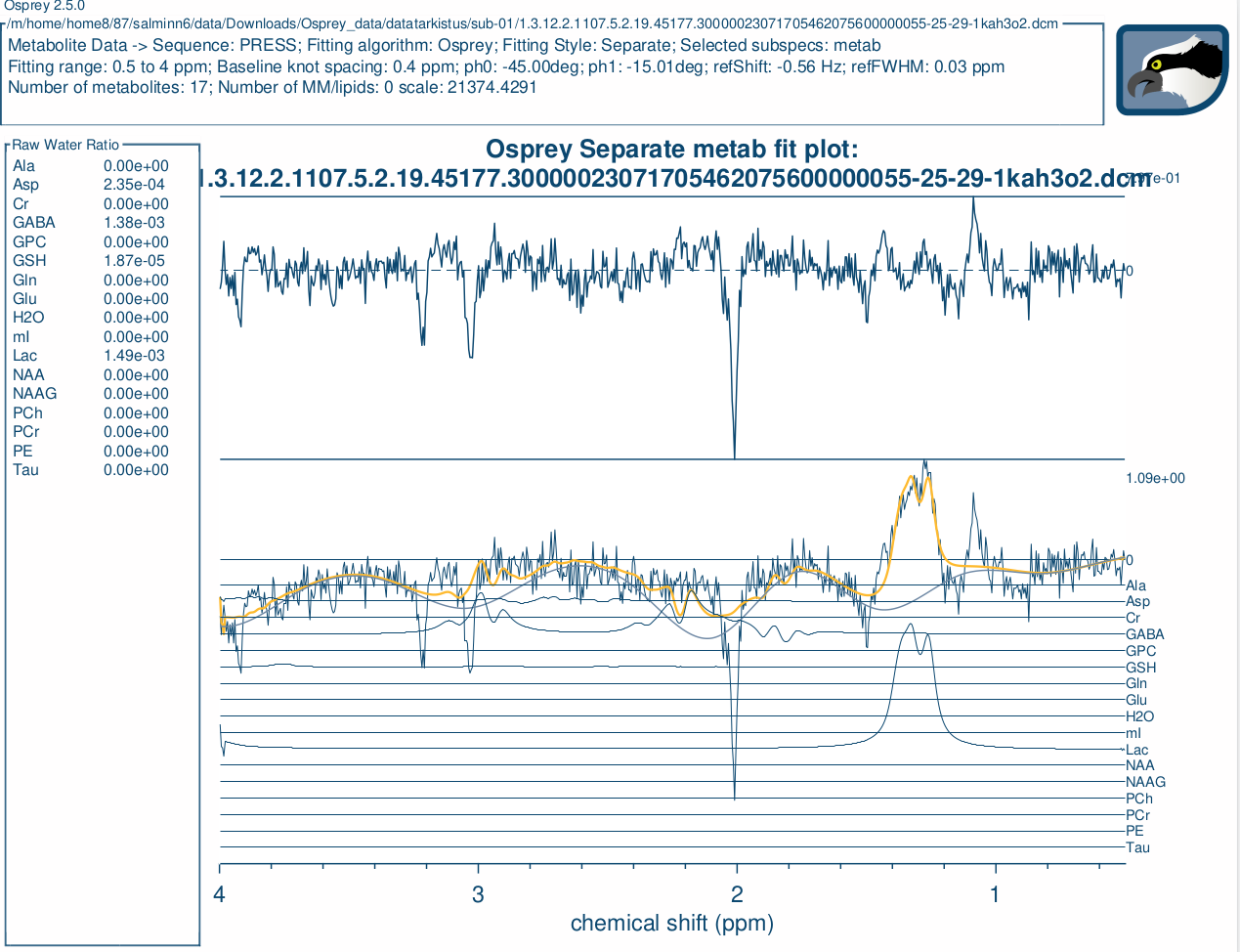
Hi, I have been having trouble with some of the data flipping upside down. Is there a reason for that? And is that due to how Osprey handles the data or because of the scanner? I am very new to MRS so all help is welcome. We use a 3T Siemens Skyra magnet and the data is in .dcm format. Below is an example of a flipped data.
Thank you for the quick response. Below is the jobfile. And the weird thing is that it does this only for a few datasets(3/50). And I believe that it happenes during the Process phase:
Hi Nella,
when I understand the Osprey code right, Osprey uses here a double Lorentzian curve fit to the Cr-Cho doublet (see FID-A\processingTools\op_creChoFit.m), so the big lipid peak with opposite sign shouldn’t make problems and the position of the two peaks also looks good.
To have a further look, you can try to modify OspreyProcess.m in line 698 (https://github.com/schorschinho/osprey/blob/develop/process/OspreyProcess.m) to
[raw,globalPhase] = op_phaseCrCho(raw, 0);
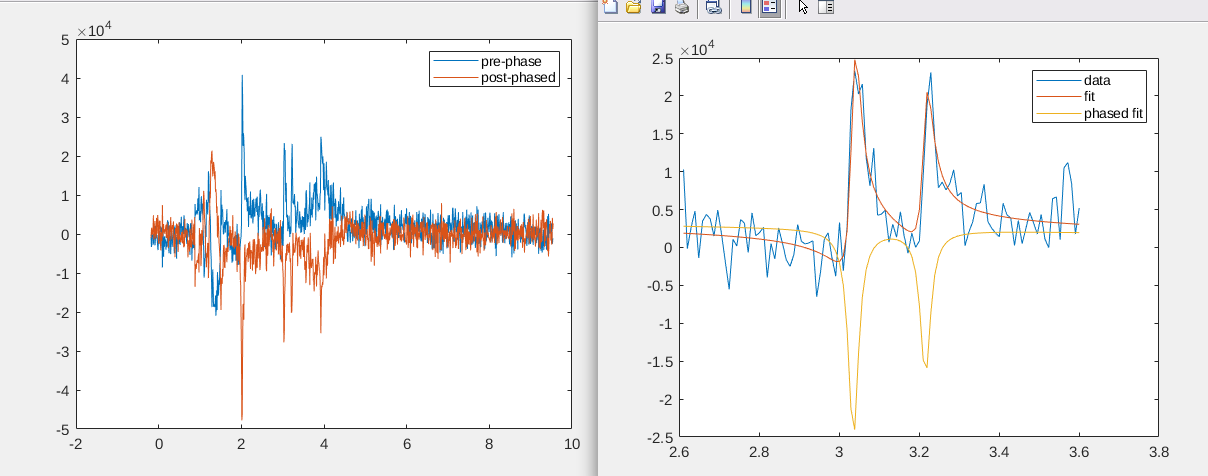
then you should have a plot of this fit (with and without phase correction) and maybe you can see if something goes wrong.
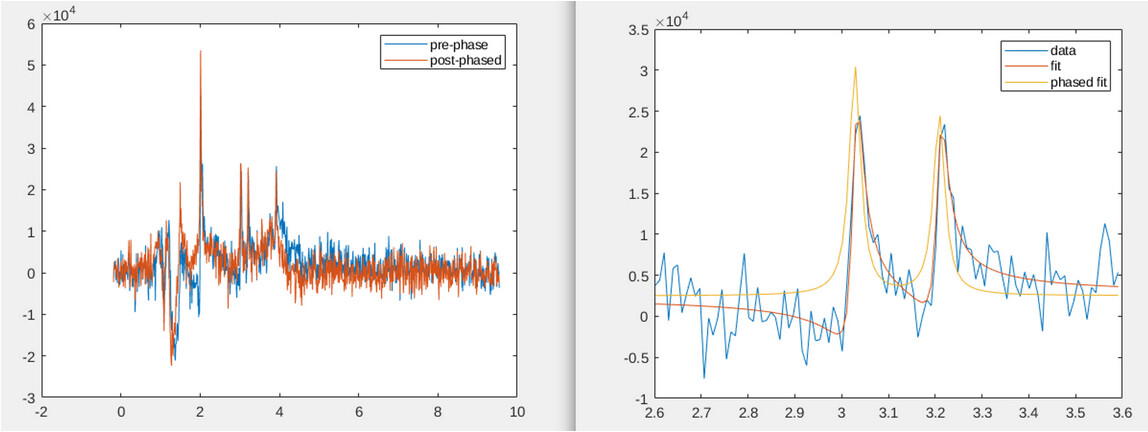
Thank you for your help. I don’t know if I completely understood what you said, but is the point that it shouldn’t matter even if the data gets flipped? Because the values that I get from the fitted plot are for example 0.00 for NAA which is not correct.
Hi Nella,
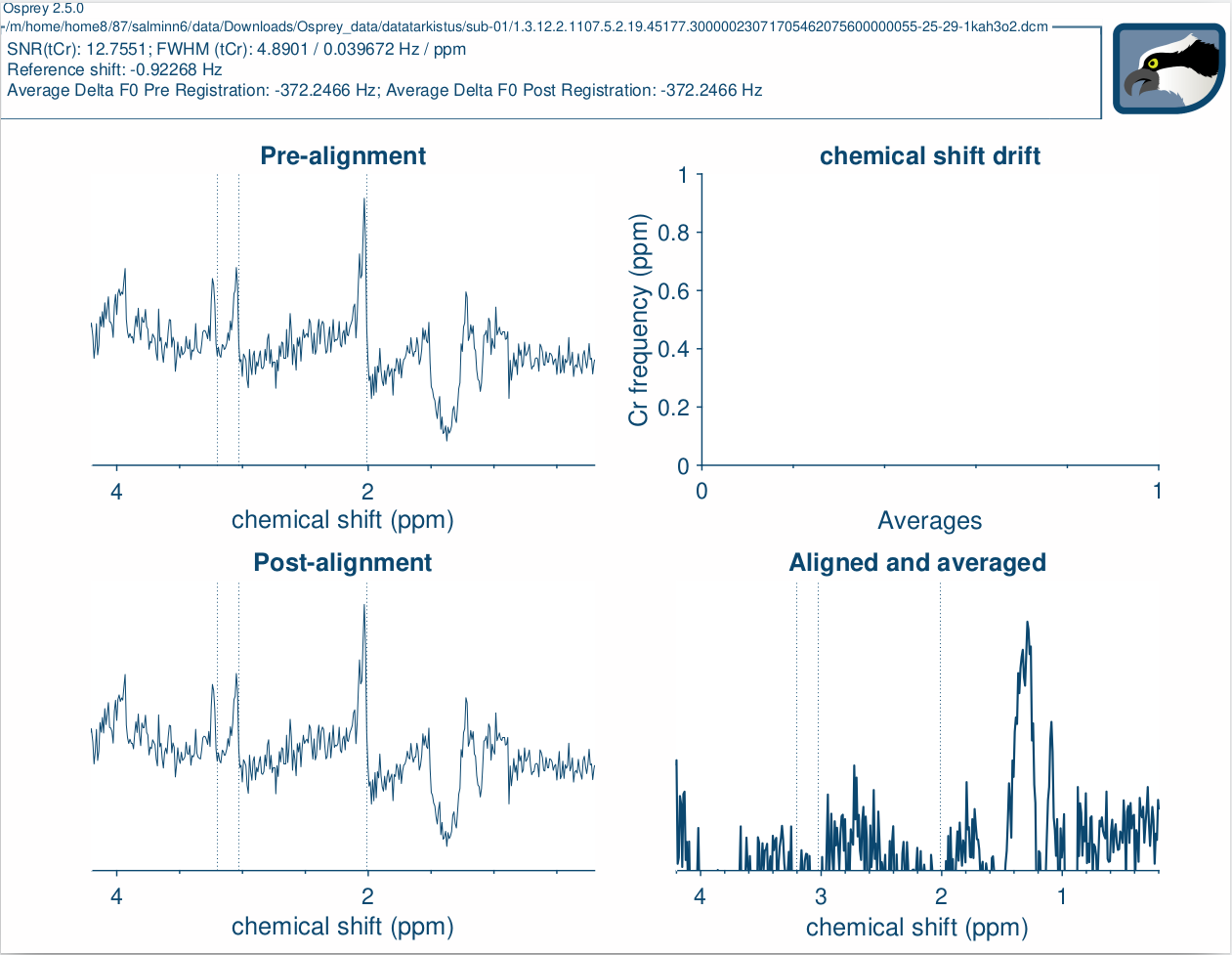
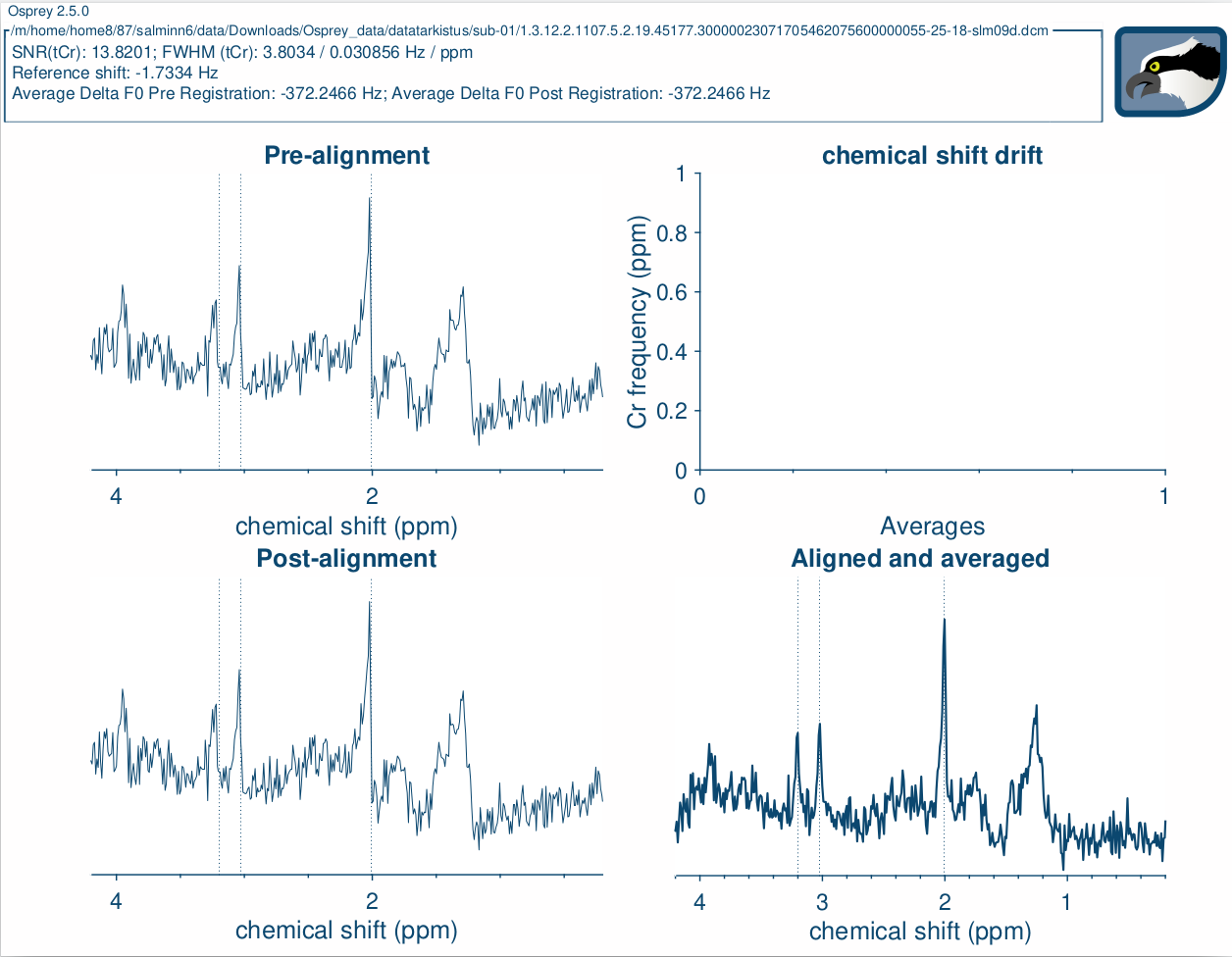
the data shouldn’t get flipped. That’s worse. The question is, are the measured data negative and the program has problems with phasing or the spectrum are good and they get worse by phasing. The latter one is here the case. In your ‘Pre-alignment’ and ‘Post-alignment’ window, your data looks ok and they are only a little bit dephased. Only after alignment and averaging the spectrum gets flipped. So, there is the next question, why Osprey did this. The main difference in your two examples is the lipid signal at around 1.3ppm. But that shouldn’t be the problem because (when I understand the Osprey script right), the doublet of Cho-Cr was used for phasing. And I think that at this point something went wrong.
Hi Nella,
‘fit’ is the actual curve we want to have after fit. For ‘phased fit’, the phase was set to zero. Normally, we would expect the plot from your edited post. I have no explanation why the ‘phased fit’ of the other plot is negative with phase 0 and it’s not obvious for me why the absorption part in op_creChoFit gets negative.
Sorry, but you have to wait for the Osprey team @Chris_Davies-Jenkins
Regarding you question about opts.ECC, this setting enables/disables the eddy-current correction using the water reference scan. I’d advise setting it to 1 as a general rule as it will correct some lineshape distortions in your data.
I don’t have an immediate explanation for why Osprey is inverting these peaks. As Heiner suggested, the overall phase correction is done using Cr and Cho, but perhaps the inverted lipid is to blame, and it’s screwing with one of the referencing steps. If you’re able to share one of the troublesome dicoms, I’m happy to dig into it a little more. (my email is cdavies9@jh.edu)
I think I found the problem. It appears that some initialization parameters for the Cr & Cho fits were not optimally set, leading to large phase errors when the baseline was significant. Once I fixed this, the test data you sent me processed without the inversion (both with and without ECC). I’ve pushed this fix to the develop branch: GitHub - schorschinho/osprey: All-in-one toolbox for processing of magnetic resonance spectroscopy data.
@zellavie, please try downloading this and running your data through again. I’m hoping this will also fix the other outliers you encountered but please let us know if you run into any other issues.
Thanks again for your help in sniffing out the problem, @hraum!